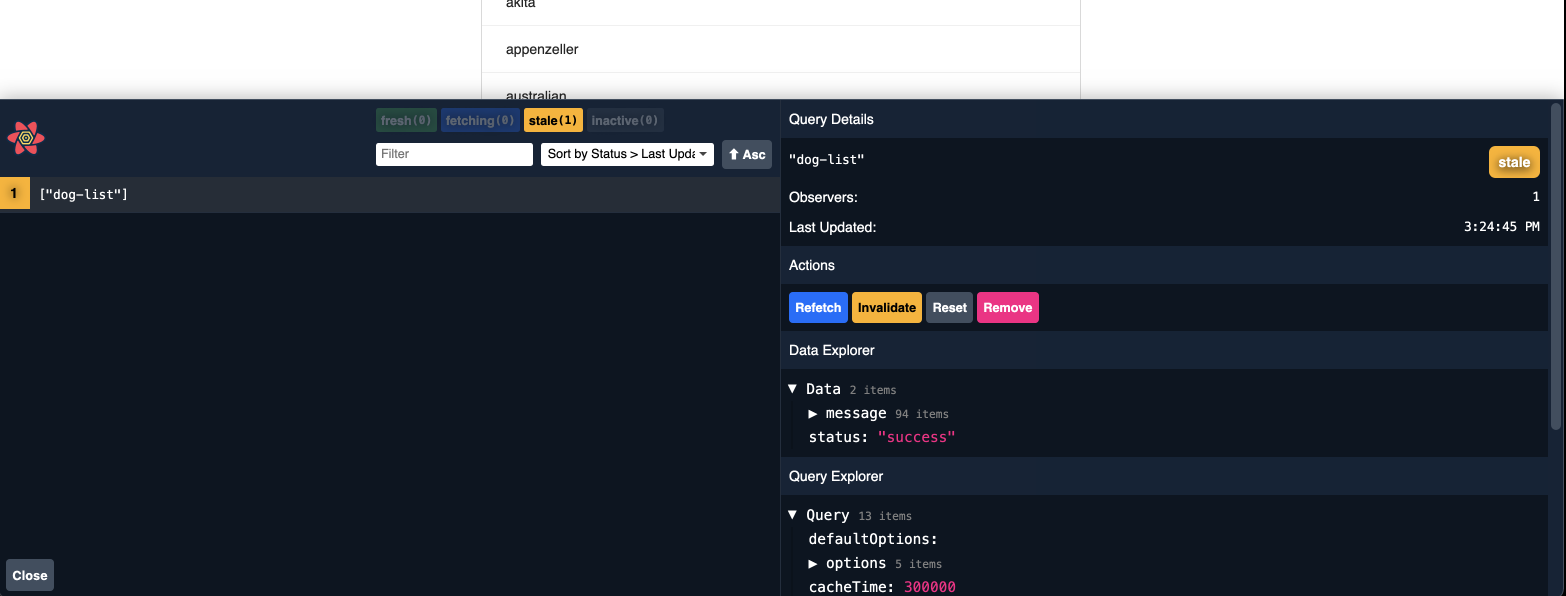
props를 통해 하위 컴포넌트에 전파하는 것이 아니라 글로벌하게 접근할 수 있는 상태 저장소 사용을 위해 recoil을 사용한다. recoil 사용이유는 간결하며 Hook스타일 개발에 적합해 보인다.
Concept & API
1) Flexible shared state: 유연하게 상태를 공유해 보자
2) Derived data and queries: 파생으로 데이터를 만들고 조회할 수 있다.
3) App-wide state observation: 애플리케이션 전체에 걸쳐 변경을 관찰할 수 있다.
atom: 상태의 단위이다.
useRecoilState: useState와 같이 read/write 가능
useSetRecoilState/useResetRecoilState: write-only
useRecoilValue: read-only, useRecoilValue(atom | selector)
selector: 파생상태를 갖거나, Async호출을 하고 싶을 경우
사용예) recoil-paint 소스
설치 및 설정
recoil을 설치한다.
$> npm install recoilESLint에 recoil hook 을 설정한다. 루트의 .eslintrc.json 파일에 useRecoilCallback 을 설정한다.
{
"root": true,
"ignorePatterns": ["**/*"],
"plugins": ["@nrwl/nx"],
"overrides": [
{
"files": ["*.ts", "*.tsx", "*.js", "*.jsx"],
"rules": {
"@nrwl/nx/enforce-module-boundaries": [
"error",
{
"enforceBuildableLibDependency": true,
"allow": [],
"depConstraints": [
{
"sourceTag": "*",
"onlyDependOnLibsWithTags": ["*"]
}
]
}
],
// 해당 하위 설정
"react-hooks/exhaustive-deps": [
"warn",
{
"additionalHooks": "useRecoilCallback"
}
]
}
},
{
"files": ["*.ts", "*.tsx"],
"extends": ["plugin:@nrwl/nx/typescript"],
"rules": {}
},
{
"files": ["*.js", "*.jsx"],
"extends": ["plugin:@nrwl/nx/javascript"],
"rules": {}
}
]
}apps/tube-csr/src/main.tsx 에 RecoilRoot를 설정한다.
import { StrictMode } from 'react';
import * as ReactDOM from 'react-dom';
import { QueryClient, QueryClientProvider } from 'react-query';
import { ReactQueryDevtools } from 'react-query/devtools';
import { RecoilRoot } from 'recoil';
import App from './app/app';
const queryClient = new QueryClient();
ReactDOM.render(
<StrictMode>
<QueryClientProvider client={queryClient}>
<RecoilRoot>
<App />
</RecoilRoot>
<ReactQueryDevtools />
</QueryClientProvider>
</StrictMode>,
document.getElementById('root')
);
state 패키지 구성 및 async 적용하기
libs/state 패키지를 생성한다.
$> nx g @nrwl/react:lib state
UPDATE workspace.json
CREATE libs/state/project.json
CREATE libs/state/.eslintrc.json
CREATE libs/state/.babelrc
CREATE libs/state/README.md
CREATE libs/state/src/index.ts
CREATE libs/state/tsconfig.json
CREATE libs/state/tsconfig.lib.json
UPDATE tsconfig.base.json
CREATE libs/state/jest.config.js
CREATE libs/state/tsconfig.spec.json
CREATE libs/state/src/lib/state.module.scss
CREATE libs/state/src/lib/state.spec.tsx
CREATE libs/state/src/lib/state.tsx
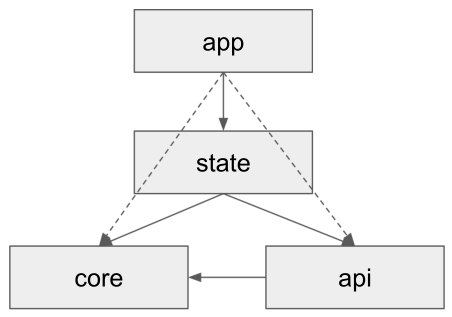
core, state, api의 사용관계도. 원칙으로 상호 참조는 할 수 없고, 단방향 사용만 가능하다.
core와 api 패키지는 최하단에 위치하고, app(application)은 core,state, api모두를 이용한다. state는 core, api를 이용한다.
조건)
- state는 selector를 통해 state 변경이 요구될 때만 aync ajax 호출이 있는 경우 api 패키지를 접근한다.
- api는 기본적으로 모든 ajax call을 처리한다.
State Custom Hook 을 만들어 기존의 useDogApi (기존 useDogList를 Api postfix로 명칭 변경)를 호출토록 한다. libs/state/src/lib 폴더에 dog.state.tsx를 만들고 다음과 같이 리팩토링한다.
- api 패키지의 useDogApi()를 호출한다.
- atom을 생성한다: dog 목록을 저장
- useEffect안에서 render이후 설정한다. useEffect를 사용하지 않으면 에러가 발생한다.
import { useEffect } from 'react';
import { atom, useRecoilState } from 'recoil';
import { useDogApi } from '@rnn-stack/api';
export const dogAtom = atom<string[]>({
key: 'dogAtom',
default: [],
});
export function useDogState(): [isLoading: boolean, dog: string[], error: Error | null] {
const { isLoading, data, error } = useDogApi();
const [dog, setDog] = useRecoilState(dogAtom);
useEffect(() => {
setDog(data?.message || []);
}, [data?.message, setDog]);
return [isLoading, dog, error];
}react-query의 반환값을 같이 넘긴다. useDogState Hook을 apps/tube-csr/src/app/dog.tsx에 적용한다. 즉, 기존 useDogApi 코드를 리팩토링한다.
import { List } from 'antd';
import { useDogState } from '@rnn-stack/state';
function DogList() {
// recoil을 사용한 custom hook 적용
const [isLoading, dog, error] = useDogState();
if (isLoading || !dog) {
return <span>loading...</span>;
}
if (error) {
return <span>Error: {error.message}</span>;
}
return (
<List
header={<div>Header</div>}
footer={<div>Footer</div>}
bordered
dataSource={dog}
renderItem={(item: string) => <List.Item>{item}</List.Item>}
/>
);
}
export default DogList;위의 경우는 api호출후 서버 state에 결과를 저장하는 과정으로 react-query를 사용해도 되지만 예로 작성해 보았다. UI에 대한 state 저장은 소개 영상을 참조한다.
https://www.youtube.com/watch?v=_ISAA_Jt9kI&t=1s
소스: https://github.com/ysyun/rnn-stack/releases/tag/hh-5
<참조>
> 한글: https://recoiljs.org/ko/
Recoil
A state management library for React.
recoiljs.org
> Awesome Recoil: https://github.com/nikhil-malviya/awesome-recoil
GitHub - nikhil-malviya/awesome-recoil: A curated list of Recoil libraries, code snippets, best practices, benchmarks and resour
A curated list of Recoil libraries, code snippets, best practices, benchmarks and resources. - GitHub - nikhil-malviya/awesome-recoil: A curated list of Recoil libraries, code snippets, best practi...
github.com
> 2021 libraries & React state mangement
https://dev.to/sfeircode/my-go-to-react-libraries-for-2021-4k1
My go-to React libraries for 2021
I’ve been working on React apps for more than 3 years now and I’ve used tons of libraries to build va...
dev.to
https://dev.to/workshub/state-management-battle-in-react-2021-hooks-redux-and-recoil-2am0
State Management Battle in React 2021: Hooks, Redux, and Recoil
Introduction: Over the years, the massive growth of React.JS has given birth to different...
dev.to
> State Management 분류
Flux: Redux, zustand
Atomic: Jotai, recoil
Proxy: mobx, valtio, overmind
프론트엔드 상태에 관한 정리 글
프론트엔드 개발에서 짜증나는건 상태관리 부분이다.몇 가지 좋은 글이 많아서 요약겸 정리를 하면 좋을 것 같다 생각이 든다.https://leerob.io/blog/react-state-management리액트 상태 관리의 역사를 다루
velog.io
> Zustand vs Redux vs Jotai vs Recoil
소스: https://github.com/redhwannacef/youtube-tutorials/blob/main/react-state-management/README.md
https://www.youtube.com/watch?v=BaEWIbxZKco
'React > Start React' 카테고리의 다른 글
| [React HH-6] 서버 사이드 렌더링 SSR - Next.JS (0) | 2021.09.08 |
|---|---|
| [React HH-4] 라이브러리 설정 - ReactQuery (0) | 2021.09.03 |
| [React HH-3] 라이브러리 설정 - Axios, RxJS (0) | 2021.08.28 |
| [React HH-2] NX 기반으로 React 개발환경 구성하기 (0) | 2021.08.25 |
| [React HH-1] 시작하는 개발자를 위한 히치하이커 (0) | 2021.08.25 |