[LCC-6] LangChain Retriever 이해
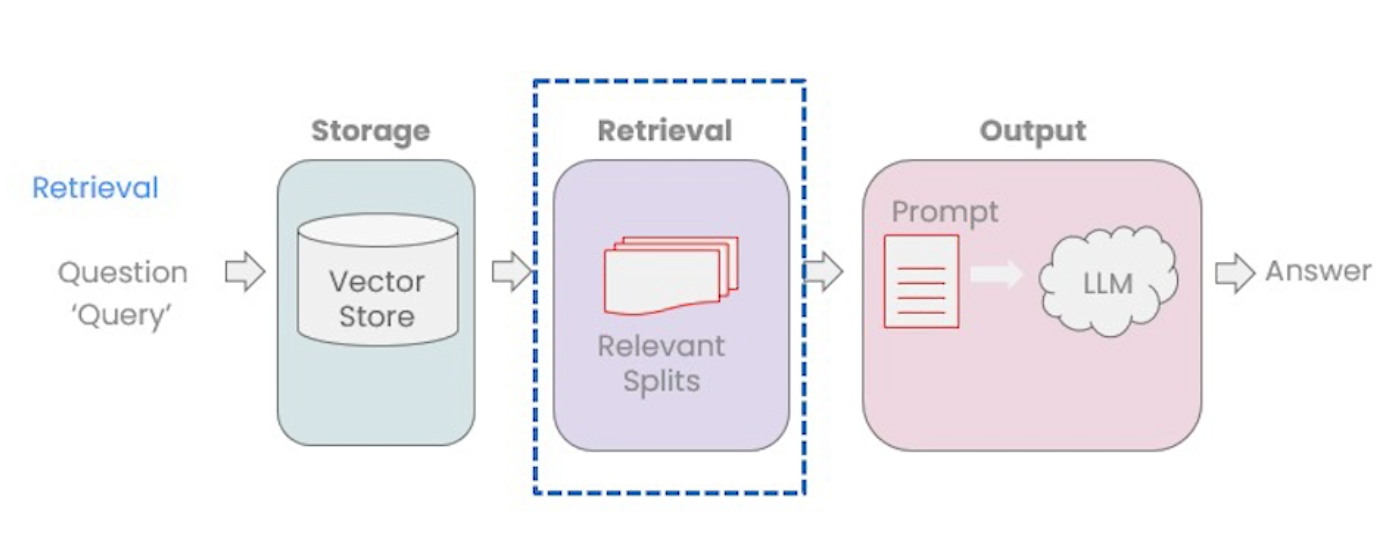
Retriever은 VectorStore에서 데이터를 검색하는 인터페이스이다. Retriever는 VectorStore에서 as_retriever() 메서드 호출로 생성한다. 리트리버의 두가지 쿼리 방식에 대해 알아보자.
- Sematic Similarity
- k: relevance 관련성 있는 것을 결과에 반영할 갯수
- Maxium Marginal relavance
- k: relevance 관련성 있는 것을 결과에 반영할 갯수
- fetch_k: diverse 다양성 있는 것을 결과에 반영할 갯수
패키지
Semantic Similarity는 의미적으로 유사한 것을 찾아준다. Reriever를 VectorStore를 통해 얻게 되면 VectoreStore 클래스의 similarity_search() 를 사용한다. 그리고, VectoreStore 클래스를 상속받은 구현체는 similarity_search가 abstractmethod 이기에 구현을 해야 한다. 예로) Chroma는 VectorStore를 상속받아 구현하고 있다.
- 관련성있는 것을 찾기 위하여 k 갯수를 설정한다.
class Chroma(VectorStore):
def similarity_search(
self,
query: str,
k: int = DEFAULT_K,
filter: Optional[Dict[str, str]] = None,
**kwargs: Any,
) -> List[Document]:
"""Run similarity search with Chroma.
Args:
query (str): Query text to search for.
k (int): Number of results to return. Defaults to 4.
filter (Optional[Dict[str, str]]): Filter by metadata. Defaults to None.
Returns:
List[Document]: List of documents most similar to the query text.
"""
docs_and_scores = self.similarity_search_with_score(
query, k, filter=filter, **kwargs
)
return [doc for doc, _ in docs_and_scores]
MMR(Maximum Marginal Relevance) 는 관련성과 다양성을 동시에 검색하여 제공한다. VectorStore의 max_marginal_relevance_search() 를 사용한다. Chroma 구현내용을 보자.
- k: 관련성 결과반영 갯수
- fetch_k: 다양성 결과반영 갯수
class Chroma(VectorStore):
def max_marginal_relevance_search(
self,
query: str,
k: int = DEFAULT_K,
fetch_k: int = 20,
lambda_mult: float = 0.5,
filter: Optional[Dict[str, str]] = None,
where_document: Optional[Dict[str, str]] = None,
**kwargs: Any,
) -> List[Document]:
"""Return docs selected using the maximal marginal relevance.
Maximal marginal relevance optimizes for similarity to query AND diversity
among selected documents.
Args:
query: Text to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
fetch_k: Number of Documents to fetch to pass to MMR algorithm.
lambda_mult: Number between 0 and 1 that determines the degree
of diversity among the results with 0 corresponding
to maximum diversity and 1 to minimum diversity.
Defaults to 0.5.
filter (Optional[Dict[str, str]]): Filter by metadata. Defaults to None.
Returns:
List of Documents selected by maximal marginal relevance.
"""
if self._embedding_function is None:
raise ValueError(
"For MMR search, you must specify an embedding function on" "creation."
)
embedding = self._embedding_function.embed_query(query)
docs = self.max_marginal_relevance_search_by_vector(
embedding,
k,
fetch_k,
lambda_mult=lambda_mult,
filter=filter,
where_document=where_document,
)
return docs
VectorStore에서 from_documents 또는 from_texts 메서도에 content와 embedding을 파라미터 설정하고 호출하면 VST 타입의 VectorStore 객체를 반환 받을 수 있다. 이를 통해 similarity_search와 max_marginal_relevance_search 를 사용할 수 있다.
class VectorStore(ABC):
@classmethod
@abstractmethod
def from_texts(
cls: Type[VST],
texts: List[str],
embedding: Embeddings,
metadatas: Optional[List[dict]] = None,
**kwargs: Any,
) -> VST:
"""Return VectorStore initialized from texts and embeddings.
Args:
texts: Texts to add to the vectorstore.
embedding: Embedding function to use.
metadatas: Optional list of metadatas associated with the texts.
Default is None.
**kwargs: Additional keyword arguments.
Returns:
VectorStore: VectorStore initialized from texts and embeddings.
"""
similarity_search와 max_marginal_relevance_search 를 사용예를 보자.
from langchain.vectorstores import Chroma
from langchain.openai import OpenAIEmbeddings
persistence_path = 'db/chroma'
embeddings = OpenAIEmbeddings()
vectorestore = Chroma(persist_directory=persistence_path, embedding_function=embeddings)
texts = [
"""홍길동을 홍길동이라 부르지 못하는 이유는 무엇인가""",
"""심청이가 물에 빠진것을 효라고 말할 수 있는가, 그것이 진심이었나""",
"""춘향이가 이몽룡을 기다른 것은 진심이었나""",
]
smalldb = Chroma.from_texts(texts, embedding=embedding)
question = "진심이라는 의미"
smalldb.similarity_search(question, k=1)
// 결과
[Document(page_content='춘향이가 이몽룡을 기다른 것은 진심이었나', metadata={})]
smalldb.max_marginal_relevance_search(question,k=2, fetch_k=3)
// 결과
[Document(page_content='춘향이가 이몽룡을 기다른 것은 진심이었나', metadata={}),
Document(page_content='심청이가 물에 빠진것을 효라고 말할 수 있는가, 그것이 진심이었나', metadata={})]
위의 두가지외에 다른 검색 타입까지 합쳐 놓은 것이 langchain_core VectorStore의 as_retriever() 이다. from_documents 또는 from_texts를 호출하면 VST (Vector Store Type) 인스턴스를 반환 받아 as_retriever()를 호출한다. as_retriever()는 langchain_community VectorStoreRetriever를 반환하고, 이는 langchain_core의 retrievers.py 파일의 BaseRetriever 클래스를 상속받아 구현하고 있다.
- 0.1.46 이후 get_relevant_documents 사용하지 않고 invoke로 대체한다.
- _get_relevant_documents 를 구현해야 한다.
- search_type
- similarity
- similarity_score_threshold : score_threshold 값 설정 이상만 결과에 반영
- mmr
- 결과값: List[Document]
class VectorStoreRetriever(BaseRetriever):
"""Base Retriever class for VectorStore."""
vectorstore: VectorStore
"""VectorStore to use for retrieval."""
search_type: str = "similarity"
"""Type of search to perform. Defaults to "similarity"."""
search_kwargs: dict = Field(default_factory=dict)
"""Keyword arguments to pass to the search function."""
allowed_search_types: ClassVar[Collection[str]] = (
"similarity",
"similarity_score_threshold",
"mmr",
)
...
class BaseRetriever(RunnableSerializable[RetrieverInput, RetrieverOutput], ABC):
def invoke(
self, input: str, config: Optional[RunnableConfig] = None, **kwargs: Any
) -> List[Document]:
"""Invoke the retriever to get relevant documents.
...
"""
...
// 하위 클래스 생성시 호출이 된다. cls는 하위 클래스이다. get_relevant_documents를 할당함.
def __init_subclass__(cls, **kwargs: Any) -> None:
super().__init_subclass__(**kwargs)
# Version upgrade for old retrievers that implemented the public
# methods directly.
if cls.get_relevant_documents != BaseRetriever.get_relevant_documents:
warnings.warn(
"Retrievers must implement abstract `_get_relevant_documents` method"
" instead of `get_relevant_documents`",
DeprecationWarning,
)
swap = cls.get_relevant_documents
cls.get_relevant_documents = ( # type: ignore[assignment]
BaseRetriever.get_relevant_documents
)
cls._get_relevant_documents = swap # type: ignore[assignment]
if (
hasattr(cls, "aget_relevant_documents")
and cls.aget_relevant_documents != BaseRetriever.aget_relevant_documents
):
warnings.warn(
"Retrievers must implement abstract `_aget_relevant_documents` method"
" instead of `aget_relevant_documents`",
DeprecationWarning,
)
aswap = cls.aget_relevant_documents
cls.aget_relevant_documents = ( # type: ignore[assignment]
BaseRetriever.aget_relevant_documents
)
cls._aget_relevant_documents = aswap # type: ignore[assignment]
parameters = signature(cls._get_relevant_documents).parameters
cls._new_arg_supported = parameters.get("run_manager") is not None
# If a V1 retriever broke the interface and expects additional arguments
cls._expects_other_args = (
len(set(parameters.keys()) - {"self", "query", "run_manager"}) > 0
)
@abstractmethod
def _get_relevant_documents(
self, query: str, *, run_manager: CallbackManagerForRetrieverRun
) -> List[Document]:
"""Get documents relevant to a query.
Args:
query: String to find relevant documents for.
run_manager: The callback handler to use.
Returns:
List of relevant documents.
"""
...
@deprecated(since="0.1.46", alternative="invoke", removal="0.3.0")
def get_relevant_documents(
....
API
langchain_core의 BaseRetriever --> langchain_core의 VectorStoreRetriever 또는 langchain_community에서 다양한 <name>Retriever 를 구현한다.
- invoke, ainvoke 호출
- get_relevant_documents 호출은 invoke 로 대체되고, v0.3.0 에서 삭제될 예정이다.

<참조>
- 공식문서: https://python.langchain.com/v0.2/docs/integrations/retrievers/
Retrievers | 🦜️🔗 LangChain
A retriever is an interface that returns documents given an unstructured query.
python.langchain.com
- LangChain KR: https://wikidocs.net/234016
01. 벡터저장소 지원 검색기(VectorStore-backed Retriever)
.custom { background-color: #008d8d; color: white; padding: 0.25em 0.5…
wikidocs.net