

LangChain 의 Document Loaders 에 대한 개념 및 패키지, API를 들여다 보자.
개념
LLM은 대규모 언어모델로 언어가 텍스트 또는 음성으로 인풋을 받 다. 이때 텍스트는 사용자가 직접 입력한 내용일 수도 있고, 첨부한 문서일 수도 있고, 텍스트가 있는 소스에 접근할 수도 있다.
- 다양한 문서 포멧 로딩
- 내용을 축출하기
- 내용을 원하는 단위로 잘 쪼개기
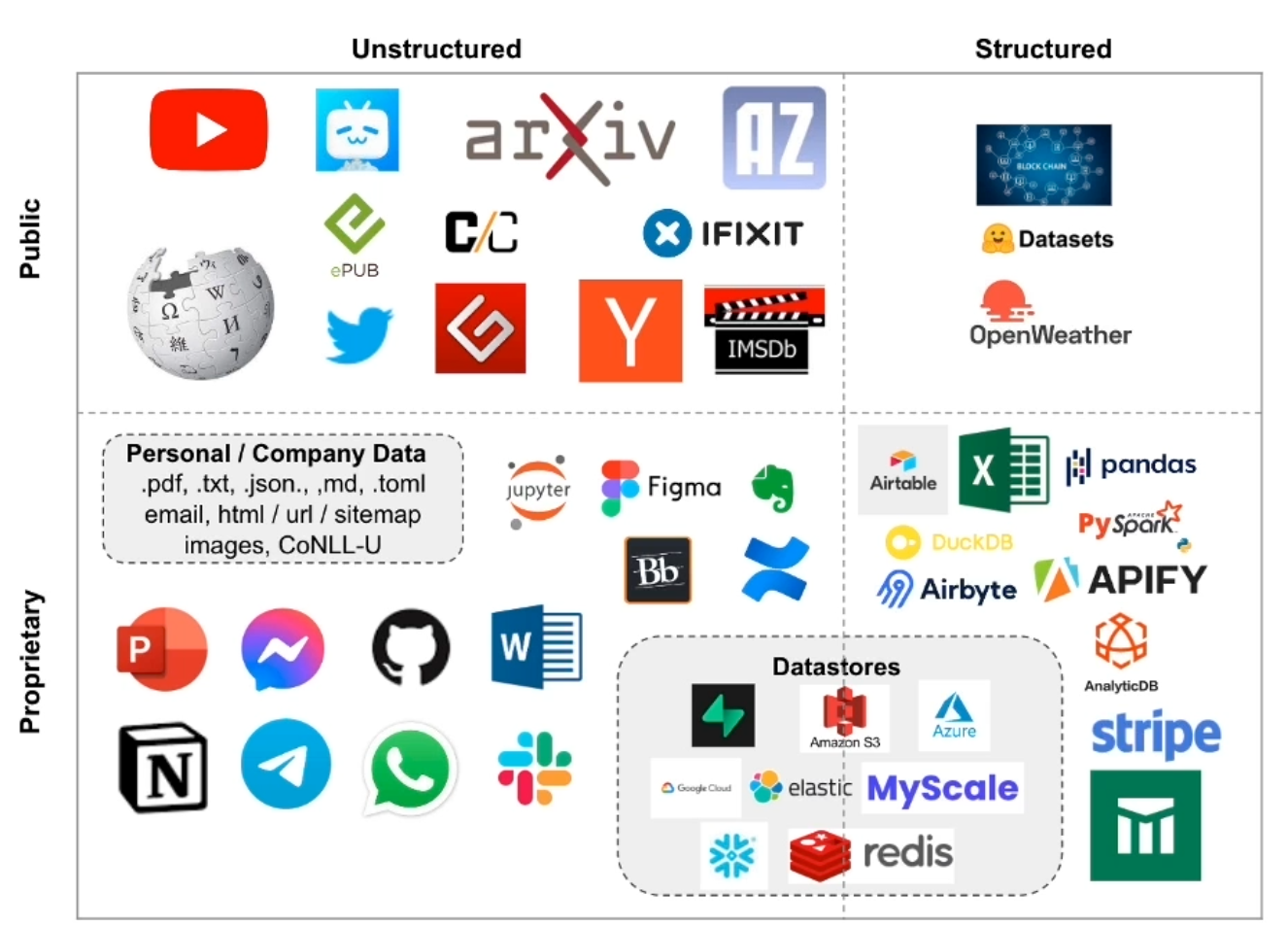
문서 종류 와 위치 (170개 가량)
- 파일: text, csv, pdf, markdown, docx, excel, json, ...
- 위치: folder, database, url, ...
- 서비스: youtube, slack, gitbook, github, git, discord, docusaurus, figma, ...
- LangChain의 document loaders 개념 설명
- LangChain의 document loaders 가이드
패키지
document_loaders 구현체들 https://python.langchain.com/v0.2/docs/integrations/document_loaders/
Document loaders | 🦜️🔗 LangChain
If you'd like to write your own document loader, see this how-to.
python.langchain.com
langchain 패키지 소스를 보면 document_loaders 패키지가 존재하고, 대부분 langchain_community 패키지 소스를 re-exporting 하고 있다.
패키지 및 로더 호출 방법
- 기본 langchain.document_loaders 에서 xxxLoader 를 임포트하여 사용한다.
//----------
// 예-1)
from langchain.document_loaders import PyPDFLoader
// 또는 from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader(FILE_PATH)
pages = loader.load()
//----------
// 예-2)
from langchain.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://github.com/langchain-ai/langchain/blob/master/README.md")
docs = loader.load()
print(docs[0].page_content[:500])
API
API 설명을 살펴보자.
- langchain_community 패키지밑으로 구현체가 존재하기에 필요한 경우 다양한 Custom Loader를 만들 수 있다.
- 추상 클래스 (Abstract Class)은 langchain_core 추상클래스인 BaseLoader를 상속받아 구현한다.
class BaseLoader(ABC):
def load(self) -> List[Document]:
"""Load data into Document objects."""
return list(self.lazy_load())
def lazy_load(self) -> Iterator[Document]:
"""Custom Loader에서 구현해야 함."""
- BaseLoader <- BasePDFLoader <- PyPDFLoader 를 구현한 클래스를 보면 lazy_load 메소드를 구현하고 있다.
class PyPDFLoader(BasePDFLoader):
def lazy_load(
self,
) -> Iterator[Document]:
"""Lazy load given path as pages."""
if self.web_path:
blob = Blob.from_data(open(self.file_path, "rb").read(), path=self.web_path) # type: ignore[attr-defined]
else:
blob = Blob.from_path(self.file_path)
- 반환값은 langchain_core의 Document 리스트이고, BaseMedia <- Document 를 통해 항시 기본적으로 접근 가능한 애트리뷰트가 있다.
- metadata : 문서 속성 정보
- page_content : 문서의 내용
class BaseMedia(Serializable):
id: Optional[str] = None
metadata: dict = Field(default_factory=dict)
class Document(BaseMedia):
page_content: str
type: Literal["Document"] = "Document"
- GenericLoader 는 다양한 문서를 로드할 수 있다. API 설명의 예제를 참조한다.
Custom Document Loader 만들기
- LangChain custom loader 가이드를 우선 참조하자.
- 구현 순서
- BaseLoader를 상속받는다.
- lazy_load 메서드를 구현한다.
- alazy_load는 옵션으로 lazy_load로 위임해도 된다.
- HWPLoader를 구현한 TeddyNote 소스를 참조하자.
<참조>
API: https://api.python.langchain.com/en/latest/langchain_api_reference.html
Source: https://github.com/langchain-ai/langchain/tree/master
GitHub - langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications
🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
github.com
Guide: https://python.langchain.com/v0.2/docs/concepts/
Conceptual guide | 🦜️🔗 LangChain
This section contains introductions to key parts of LangChain.
python.langchain.com
langchain-teddynote/langchain_teddynote/document_loaders/hwp.py at main · teddylee777/langchain-teddynote
LangChain 을 더 쉽게 구현하기 위한 유틸 함수, 클래스를 만들어서 패키지로 배포하였습니다. - teddylee777/langchain-teddynote
github.com
- LangChain KR: https://wikidocs.net/253706
01. 도큐먼트(Document) 의 구조
.custom { background-color: #008d8d; color: white; padding: 0.25em 0.…
wikidocs.net
'LLM FullStacker > LangChain' 카테고리의 다른 글
| [LCC-4] LangChain Embedding Model 이해 (0) | 2024.08.07 |
|---|---|
| [LCC-3] LangChain Splitter 이해 (0) | 2024.08.06 |
| [LCC-1] LangChain Concept - Components & RAG (0) | 2024.08.04 |
| [LangChain] LangChain is like Spring Framework for LLM (0) | 2024.06.30 |
| [LangSmith] LLM Management 시작하기 (0) | 2024.06.29 |

