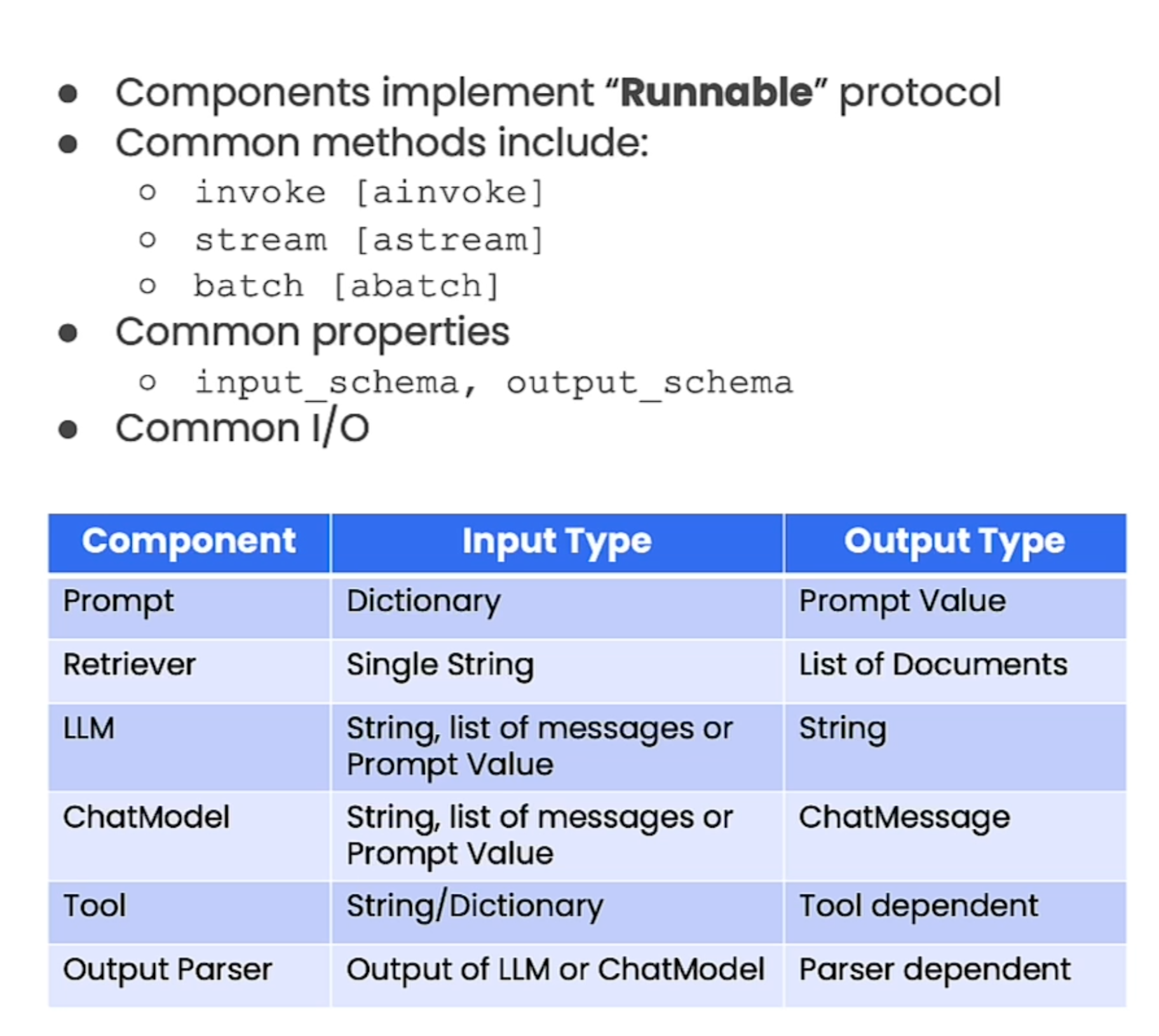
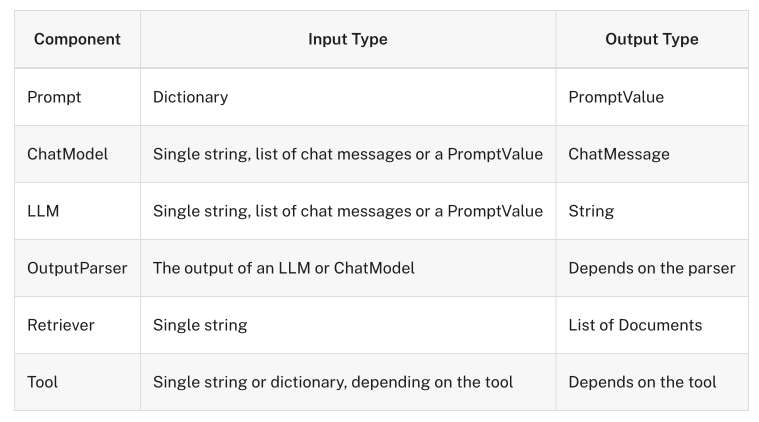
RunnableConfig는 체인생성후 Runnble의 필드값을 변경하거나, Runnable을 교체하라 수 있다.
configurable_fields 메서드 이해
Runnable의 특정 필드값을 설정할 수 있도록 해준다. runnable의 .bind 메서드와 관련이 있다.
- RunnableSerializable 클래스의 configurable_fileds 메서드 (소스)
- Model 생성시 configurable_fileds 사설정 -> Model 인스턴스 with_config 런타임 설정
class RunnableSerializable(Serializable, Runnable[Input, Output]):
"""Runnable that can be serialized to JSON."""
def configurable_fields(
self, **kwargs: AnyConfigurableField
) -> RunnableSerializable[Input, Output]:
"""Configure particular Runnable fields at runtime.
Args:
**kwargs: A dictionary of ConfigurableField instances to configure.
Returns:
A new Runnable with the fields configured.
.. code-block:: python
from langchain_core.runnables import ConfigurableField
from langchain_openai import ChatOpenAI
model = ChatOpenAI(max_tokens=20).configurable_fields(
max_tokens=ConfigurableField(
id="output_token_number",
name="Max tokens in the output",
description="The maximum number of tokens in the output",
)
)
# max_tokens = 20
print(
"max_tokens_20: ",
model.invoke("tell me something about chess").content
)
# max_tokens = 200
print("max_tokens_200: ", model.with_config(
configurable={"output_token_number": 200}
).invoke("tell me something about chess").content
)
"""
from langchain_core.runnables.configurable import RunnableConfigurableFields
for key in kwargs:
if key not in self.__fields__:
raise ValueError(
f"Configuration key {key} not found in {self}: "
f"available keys are {self.__fields__.keys()}"
)
return RunnableConfigurableFields(default=self, fields=kwargs)
Runnable 클래스의 with_config 메서드
class Runnable(Generic[Input, Output], ABC):
... 중략 ...
def with_config(
self,
config: Optional[RunnableConfig] = None,
# Sadly Unpack is not well-supported by mypy so this will have to be untyped
**kwargs: Any,
) -> Runnable[Input, Output]:
"""
Bind config to a Runnable, returning a new Runnable.
Args:
config: The config to bind to the Runnable.
kwargs: Additional keyword arguments to pass to the Runnable.
Returns:
A new Runnable with the config bound.
"""
return RunnableBinding(
bound=self,
config=cast(
RunnableConfig,
{**(config or {}), **kwargs},
), # type: ignore[misc]
kwargs={},
)
실제 예제
- Model 생성시 ConfigurableField 통해 설정
- model 인스턴스 사용시 with_config 통해 설정
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import ConfigurableField
from langchain_openai import ChatOpenAI
model = ChatOpenAI(temperature=0).configurable_fields(
temperature=ConfigurableField(
id="llm_temperature",
name="LLM Temperature",
description="The temperature of the LLM",
)
)
//--- case-1
model.invoke("pick a random number")
// 결과
AIMessage(content='17', response_metadata={'token_usage': {'completion_tokens': 1, 'prompt_tokens': 11, 'total_tokens': 12}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_c2295e73ad', 'finish_reason': 'stop', 'logprobs': None}, id='run-ba26a0da-0a69-4533-ab7f-21178a73d303-0')
//--- case-2
model.with_config(configurable={"llm_temperature": 0.9}).invoke("pick a random number")
// 결과
AIMessage(content='12', response_metadata={'token_usage': {'completion_tokens': 1, 'prompt_tokens': 11, 'total_tokens': 12}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_c2295e73ad', 'finish_reason': 'stop', 'logprobs': None}, id='run-ba8422ad-be77-4cb1-ac45-ad0aae74e3d9-0')
//--- case-3
prompt = PromptTemplate.from_template("Pick a random number above {x}")
chain = prompt | model
chain.invoke({"x": 0})
// 결과
AIMessage(content='27', response_metadata={'token_usage': {'completion_tokens': 1, 'prompt_tokens': 14, 'total_tokens': 15}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_c2295e73ad', 'finish_reason': 'stop', 'logprobs': None}, id='run-ecd4cadd-1b72-4f92-b9a0-15e08091f537-0')
//--- case-4
chain.with_config(configurable={"llm_temperature": 0.9}).invoke({"x": 0})
// 결과
AIMessage(content='35', response_metadata={'token_usage': {'completion_tokens': 1, 'prompt_tokens': 14, 'total_tokens': 15}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_c2295e73ad', 'finish_reason': 'stop', 'logprobs': None}, id='run-a916602b-3460-46d3-a4a8-7c926ec747c0-0')
configurable_alternatives 메서드 이해
Chain에 연결할 Runnable을 교체할 수 있게 한다.
class RunnableSerializable(Serializable, Runnable[Input, Output]):
... 중략 ...
def configurable_alternatives(
self,
which: ConfigurableField,
*,
default_key: str = "default",
prefix_keys: bool = False,
**kwargs: Union[Runnable[Input, Output], Callable[[], Runnable[Input, Output]]],
) -> RunnableSerializable[Input, Output]:
"""Configure alternatives for Runnables that can be set at runtime.
Args:
which: The ConfigurableField instance that will be used to select the
alternative.
default_key: The default key to use if no alternative is selected.
Defaults to "default".
prefix_keys: Whether to prefix the keys with the ConfigurableField id.
Defaults to False.
**kwargs: A dictionary of keys to Runnable instances or callables that
return Runnable instances.
Returns:
A new Runnable with the alternatives configured.
.. code-block:: python
from langchain_anthropic import ChatAnthropic
from langchain_core.runnables.utils import ConfigurableField
from langchain_openai import ChatOpenAI
model = ChatAnthropic(
model_name="claude-3-sonnet-20240229"
).configurable_alternatives(
ConfigurableField(id="llm"),
default_key="anthropic",
openai=ChatOpenAI()
)
# uses the default model ChatAnthropic
print(model.invoke("which organization created you?").content)
# uses ChatOpenAI
print(
model.with_config(
configurable={"llm": "openai"}
).invoke("which organization created you?").content
)
"""
from langchain_core.runnables.configurable import (
RunnableConfigurableAlternatives,
)
return RunnableConfigurableAlternatives(
which=which,
default=self,
alternatives=kwargs,
default_key=default_key,
prefix_keys=prefix_keys,
)
실제 예제
- Anthropic 모델 생성시, OpenAI 모델을 alternative로 설정한다.
- 상황에 따라 OpenAI 모델을 사용한다.
from langchain_anthropic import ChatAnthropic
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import ConfigurableField
from langchain_openai import ChatOpenAI
llm = ChatAnthropic(
model="claude-3-haiku-20240307", temperature=0
).configurable_alternatives(
# This gives this field an id
# When configuring the end runnable, we can then use this id to configure this field
ConfigurableField(id="llm"),
# This sets a default_key.
# If we specify this key, the default LLM (ChatAnthropic initialized above) will be used
default_key="anthropic",
# This adds a new option, with name `openai` that is equal to `ChatOpenAI()`
openai=ChatOpenAI(),
# This adds a new option, with name `gpt4` that is equal to `ChatOpenAI(model="gpt-4")`
gpt4=ChatOpenAI(model="gpt-4"),
# You can add more configuration options here
)
prompt = PromptTemplate.from_template("Tell me a joke about {topic}")
chain = prompt | llm
//--- case-1
# By default it will call Anthropic
chain.invoke({"topic": "bears"})
// 결과
AIMessage(content="Here's a bear joke for you:\n\nWhy don't bears wear socks? \nBecause they have bear feet!\n\nHow's that? I tried to come up with a simple, silly pun-based joke about bears. Puns and wordplay are a common way to create humorous bear jokes. Let me know if you'd like to hear another one!", response_metadata={'id': 'msg_018edUHh5fUbWdiimhrC3dZD', 'model': 'claude-3-haiku-20240307', 'stop_reason': 'end_turn', 'stop_sequence': None, 'usage': {'input_tokens': 13, 'output_tokens': 80}}, id='run-775bc58c-28d7-4e6b-a268-48fa6661f02f-0')
//--- case-2
# We can use `.with_config(configurable={"llm": "openai"})` to specify an llm to use
chain.with_config(configurable={"llm": "openai"}).invoke({"topic": "bears"})
// 결과
AIMessage(content="Why don't bears like fast food?\n\nBecause they can't catch it!", response_metadata={'token_usage': {'completion_tokens': 15, 'prompt_tokens': 13, 'total_tokens': 28}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_c2295e73ad', 'finish_reason': 'stop', 'logprobs': None}, id='run-7bdaa992-19c9-4f0d-9a0c-1f326bc992d4-0')
//--- case-3
# If we use the `default_key` then it uses the default
chain.with_config(configurable={"llm": "anthropic"}).invoke({"topic": "bears"})
// 결과
AIMessage(content="Here's a bear joke for you:\n\nWhy don't bears wear socks? \nBecause they have bear feet!\n\nHow's that? I tried to come up with a simple, silly pun-based joke about bears. Puns and wordplay are a common way to create humorous bear jokes. Let me know if you'd like to hear another one!", response_metadata={'id': 'msg_01BZvbmnEPGBtcxRWETCHkct', 'model': 'claude-3-haiku-20240307', 'stop_reason': 'end_turn', 'stop_sequence': None, 'usage': {'input_tokens': 13, 'output_tokens': 80}}, id='run-59b6ee44-a1cd-41b8-a026-28ee67cdd718-0')
bind 메서드 이해
Runnable 클래스의 bind 메서드
- RunnableBinding 클래스 인스턴스를 리턴한다.
class Runnable(Generic[Input, Output], ABC):
... 중략 ...
def bind(self, **kwargs: Any) -> Runnable[Input, Output]:
"""
Bind arguments to a Runnable, returning a new Runnable.
Useful when a Runnable in a chain requires an argument that is not
in the output of the previous Runnable or included in the user input.
Args:
kwargs: The arguments to bind to the Runnable.
Returns:
A new Runnable with the arguments bound.
Example:
.. code-block:: python
from langchain_community.chat_models import ChatOllama
from langchain_core.output_parsers import StrOutputParser
llm = ChatOllama(model='llama2')
# Without bind.
chain = (
llm
| StrOutputParser()
)
chain.invoke("Repeat quoted words exactly: 'One two three four five.'")
# Output is 'One two three four five.'
# With bind.
chain = (
llm.bind(stop=["three"])
| StrOutputParser()
)
chain.invoke("Repeat quoted words exactly: 'One two three four five.'")
# Output is 'One two'
"""
return RunnableBinding(bound=self, kwargs=kwargs, config={})
- bind: Bind kwargs to pass to the underlying Runnable when running it.
- with_config: Bind config to pass to the underlying Runnable when running it.
- with_listeners: Bind lifecycle listeners to the underlying Runnable.
- with_types: Override the input and output types of the underlying Runnable.
- with_retry: Bind a retry policy to the underlying Runnable.
- with_fallbacks: Bind a fallback policy to the underlying Runnable.
class RunnableBinding(RunnableBindingBase[Input, Output]):
"""Wrap a Runnable with additional functionality.
A RunnableBinding can be thought of as a "runnable decorator" that
preserves the essential features of Runnable; i.e., batching, streaming,
and async support, while adding additional functionality.
Any class that inherits from Runnable can be bound to a `RunnableBinding`.
Runnables expose a standard set of methods for creating `RunnableBindings`
or sub-classes of `RunnableBindings` (e.g., `RunnableRetry`,
`RunnableWithFallbacks`) that add additional functionality.
These methods include:
- `bind`: Bind kwargs to pass to the underlying Runnable when running it.
- `with_config`: Bind config to pass to the underlying Runnable when running it.
- `with_listeners`: Bind lifecycle listeners to the underlying Runnable.
- `with_types`: Override the input and output types of the underlying Runnable.
- `with_retry`: Bind a retry policy to the underlying Runnable.
- `with_fallbacks`: Bind a fallback policy to the underlying Runnable.
Example:
`bind`: Bind kwargs to pass to the underlying Runnable when running it.
.. code-block:: python
# Create a Runnable binding that invokes the ChatModel with the
# additional kwarg `stop=['-']` when running it.
from langchain_community.chat_models import ChatOpenAI
model = ChatOpenAI()
model.invoke('Say "Parrot-MAGIC"', stop=['-']) # Should return `Parrot`
# Using it the easy way via `bind` method which returns a new
# RunnableBinding
runnable_binding = model.bind(stop=['-'])
runnable_binding.invoke('Say "Parrot-MAGIC"') # Should return `Parrot`
Can also be done by instantiating a RunnableBinding directly (not recommended):
.. code-block:: python
from langchain_core.runnables import RunnableBinding
runnable_binding = RunnableBinding(
bound=model,
kwargs={'stop': ['-']} # <-- Note the additional kwargs
)
runnable_binding.invoke('Say "Parrot-MAGIC"') # Should return `Parrot`
"""
<참조>
- LangChain Configurable: https://python.langchain.com/v0.2/docs/how_to/configure/
How to configure runtime chain internals | 🦜️🔗 LangChain
This guide assumes familiarity with the following concepts:
python.langchain.com
- LangChain KR: https://wikidocs.net/235704
06. configurable_fields, configurable_alternatives
.custom { background-color: #008d8d; color: white; padding: 0.25em 0.5…
wikidocs.net
'LLM FullStacker > LangChain' 카테고리의 다른 글
| [LCC-10] LangChain RunnableParallel, @chain 이해 (0) | 2024.08.13 |
|---|---|
| [LCC-9] LangChain Runnable 이해 (0) | 2024.08.12 |
| [LCC-7] LangChain PromptTemplate 이해 (0) | 2024.08.11 |
| [LCC-6] LangChain Retriever 이해 (0) | 2024.08.10 |
| [LCC-5] LangChain VectorStore 이해 (0) | 2024.08.09 |